
Recently, during the migration of one of our accounts to Grail, we encountered concerns regarding DDU metrics consumption. It came to our attention that we were collecting certain logs that were of lower priority and were being stored for the standard 35-day retention period, just like all other logs. To address this, we explored the newly introduced feature of custom Grail buckets with shorter retention periods for less critical logs, which we previously discussed in a blog post.
We recognized that the default 35-day retention period was unnecessary for specific log types, especially in non-production environments. Our recommendation was to create a new bucket with a 10-day retention period and redirect such logs accordingly.
However, we faced an initial challenge due to the documentation not being entirely up-to-date. We discovered that the process of creating custom buckets was currently only possible through the new Bucket Management API or SDK. Subsequently, we sought assistance through a support ticket to clarify this process. Fortunately, much of the information required is now available in the official documentation, and we'll provide a brief overview of the process below.
Step 1: Create a new Custom Bucket
This has to be done via the Bucket Management API (follow these steps to navigate there).
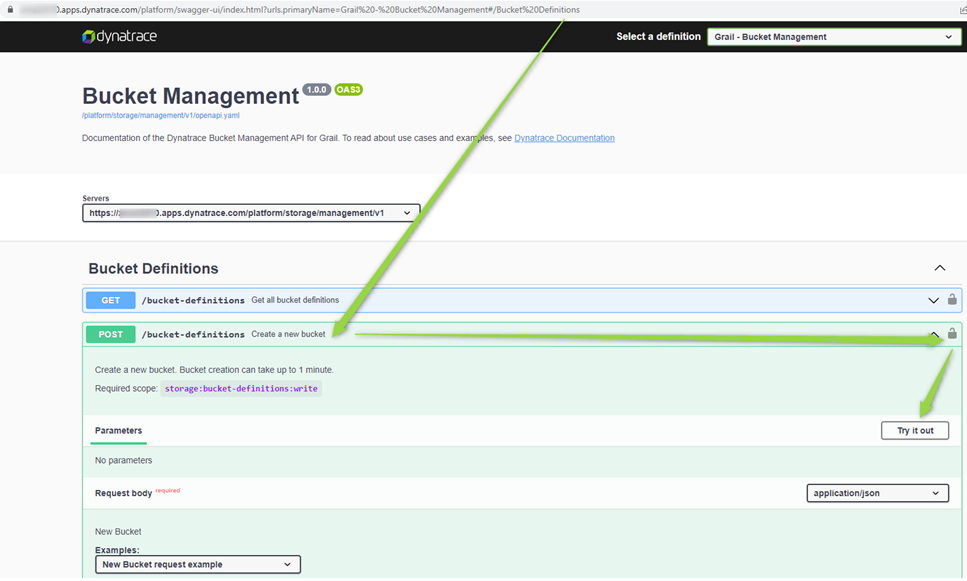
Note: Make sure the User who is creating the Buckets via the API has the necessary permissions:
Create a Policy with the definition:
ALLOW storage:bucket-definitions:read;
ALLOW storage:bucket-definitions:write;
Assign that Policy to a User Group then assign the User Group to the User.

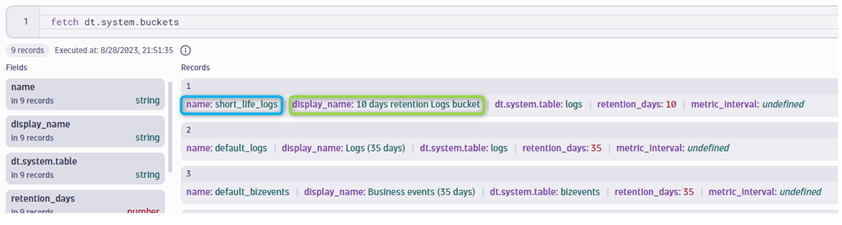
In our case, we created a bucket short_life_logs with a visible name "10 days retention Logs bucket" associated with it. You can immediately check it via Grail as well:
Step 2: Identify the logs that should be redirected to the new Custom Bucket
For example, it can be Kubernetes logs from non-prod clusters:
fetch logs
| filter isNotNull(`dt.kubernetes.cluster.name`) and not matchesPhrase(dt.kubernetes.cluster.name , "*-prd-*")
| summarize count(), by: {dt.kubernetes.cluster.name}
Or, as in our example, Microsoft Defender for Cloud logs:

This has to be done via the Bucket Management.
Step 3: Create a Log Bucket Assignment Rule
Now we have a Custom bucket and the DQL that identifies the logs, it is time to create a log bucket assignment rule. In the Dynatrace menu, go to Settings > Log monitoring > Bucket assignment and create a rule. In our example:

More information about Bucket assignment process can be found here.
Step 4: Verify the results Give it some time and check where the logs go now with the help of the Grail queries. In our case:

That's it. The retentions (and associated cost!) are reduced by 25 days.
Understanding your log ingestion within Dynatrace is crucial because it allows you to optimize costs effectively. Collecting logs indiscriminately can lead to unnecessary expenses. With Dynatrace's flexible log retention options, you can align your log storage strategy with the importance of the data, ensuring cost-efficiency. For guidance on managing your Dynatrace log ingestion, feel free to reach out to our team here hello@visibilityplatforms.com
Comments